不得不说很多事情和灵感都来源于一些极小的提示和意外———上午照例喝着味全吃着香肠跑着脚本,结果在上一篇文章里有记述(Dropout针对于LSTM的结果部分)。然而我无意中看到了引用的一部分源码的作者的一小句注释:Use GRU for fun. 好吧,周日上午这么闲,试试看咯,反正用的是库,改两行代码而已嘛~
GRU的大致结构我之前算是有所了解,和LSTM区别和作用都不是太大,相比于LSTM少了一些功能单元。但结果自然是令人吃惊的,否则我也不会写这篇博文:GRU在5个epoch之后不仅用时大概仅为LSTM的2/3左右,准确率甚至略胜于LSTM(虽然差距在小数点后第二位)。毫无疑问,这让我对这个结构单元产生了兴趣。那么,就来好好研究一下这家伙吧。
GRU的Review一般认为来自于两篇论文,均可认为来自于蒙特利尔大学Bengio组的团队。本文所有图解均来源于这两篇论文:
1)On the Properties of Neural Machine Translation: Encoder–Decoder Approaches。GRU的起始论文,主要用于RNN和CNN,当时的应用领域主要是智能翻译(Machine Translation);
2)Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling。GRU和其它递归单元(recurrent units),尤其是LSTM的比较以及应用的拓展。和上一篇博文一样,我本人侧重于第二篇文章。
Overview of Gated Recurrent Unit
Gated Recurrent Unit(GRU)是Bengio大牛在蒙特利尔大学的团队于2014年开发出来的,由于结构相似,很多人都会拿早些的LSTM和这个单元进行比较来介绍它,这个在后文细说。一开始GRU并不叫这个名字而是叫Gate Hidden Neurons,不过计算结构和现在比并没有什么变化。
那么,对,还是话说简单点,上图:

上面也说过,相比于LSTM,GRU的结构看上去简单一些,门的数量少了一个(一个update gate,一个reset gate),也不是先求和再激活而是直接将update gate的输出数据放入激活函数进行计算。
GRU的计算公式相比于LSTM自然也是简单了一个档次,详见第二篇文章Section 3.2部分。在这里贴出其中一个公式:

这是GRU的所谓的“记忆保存”公式,达到的效果和LSTM的激活函数类似。不同之处在于GRU使用的是插值,LSTM则直接将过去的数据切了一部分之后放进cell。
其他计算公式如果对LSTM之前有所了解的话应该并不难懂。单从结构上来看,LSTM对于数据的记忆能力更强,但GRU对于前一时间点的信息控制做得更好(Candidate activation直接和输入相连)。因此这么看孰优孰劣并不好说。
Effect on Sequential Data
所以第二篇文章将传统的tanh-RNN,GRU-RNN和LSTM-RNN进行了对比,观察它们在对时序数据上建模中的表现。数据集分为两种:复合型音乐信号(Polyphonic music Signal)和语音信号(Speech Signal)。三种网络的规模和测试的结果如下:
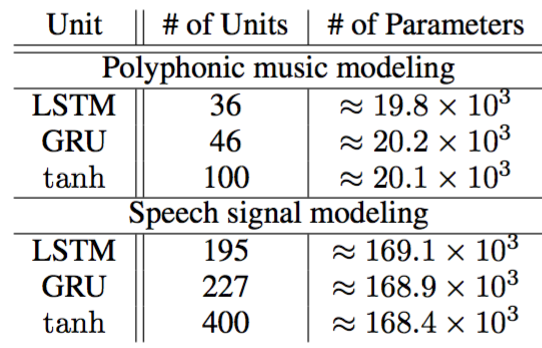
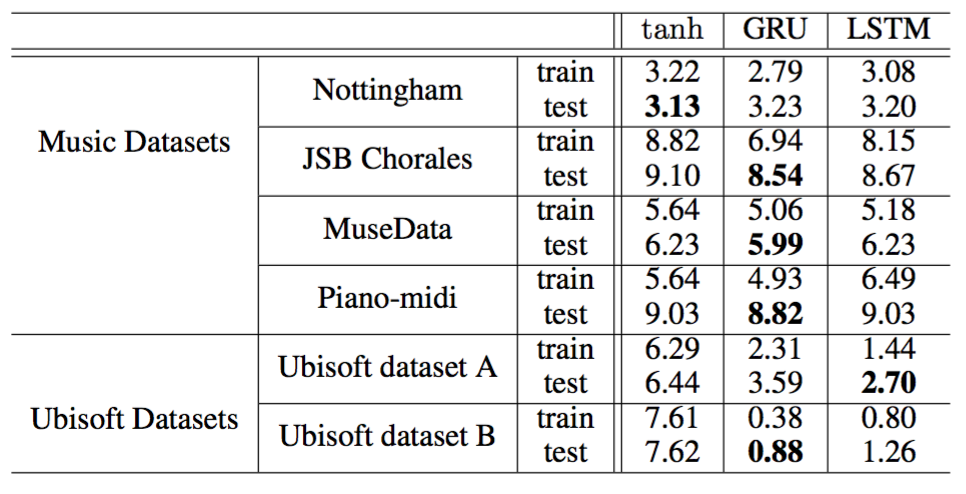
从结果可以看出,GRU在Music Dataset上面的表现吊打LSTM,而之后的validation收敛速率上来看GRU同样最优。但Ubisoft Speeech Dataset里GRU的表现就不那么强势。下图是validation的收敛速率比较。
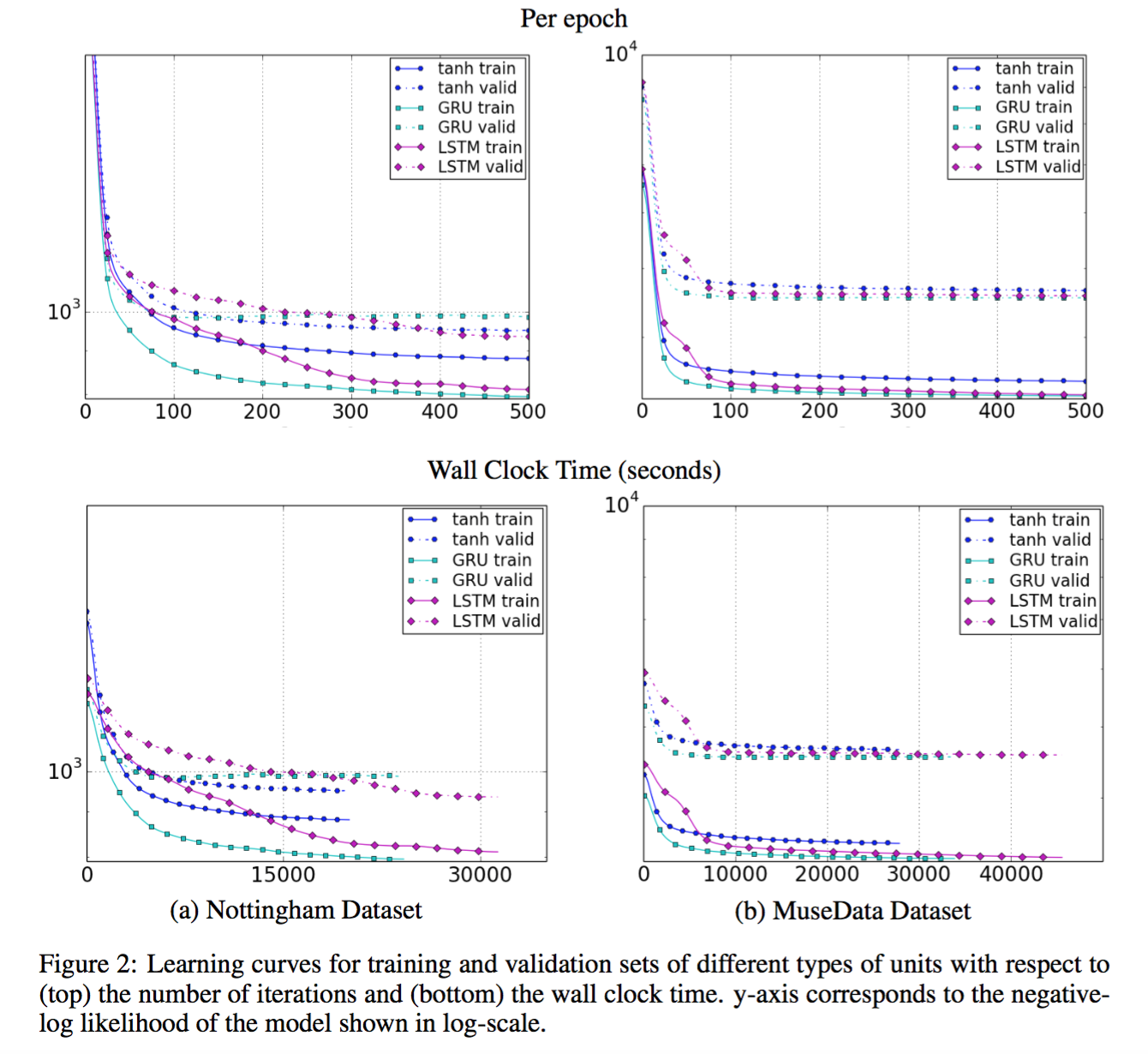
Conclusion
这篇博文算是我个人对GRU的一个记录,刚正经接触两天自然是没什么太过深刻的理解(可能以后有,到时再更新?)。不过就应用方面,GRU在Music Dataset上出色的表现让我更倾向于在我的project里选择这个网络。实习的日子已经不多,最后时刻看看能不能用GRU搞点大新闻,哈哈~虽然其实不大可能~
OK,吃午饭咯~祝家里的那位物理老大爷生日快乐!!!你永远是我的榜样!!!